word vectors can be simple vectors of weights. Simple encoding includes the one-hot encoding where we have a set of N words and a word is represented by the vector of all zeroes with a single one at the element's position.
Example:
[King, Queen, Man, Woman, Child]
we can represent Queen as
[0,1,0,0,0]A cooler representation is a distributed representation. Each word can be represented by a vector of weights, where each weight we can assign to be a trait and we can have thousands of traits.
Example:
Royalty Masculinity Femininity
King [0.999, 0.965, 0.032, ...
Queen [0.95, 0.05, 0,98, ...
Woman [0.01, 0.01, 0.99, ...In this way, these word vectors represent the meaning of the words through labelled weighted dimensions.
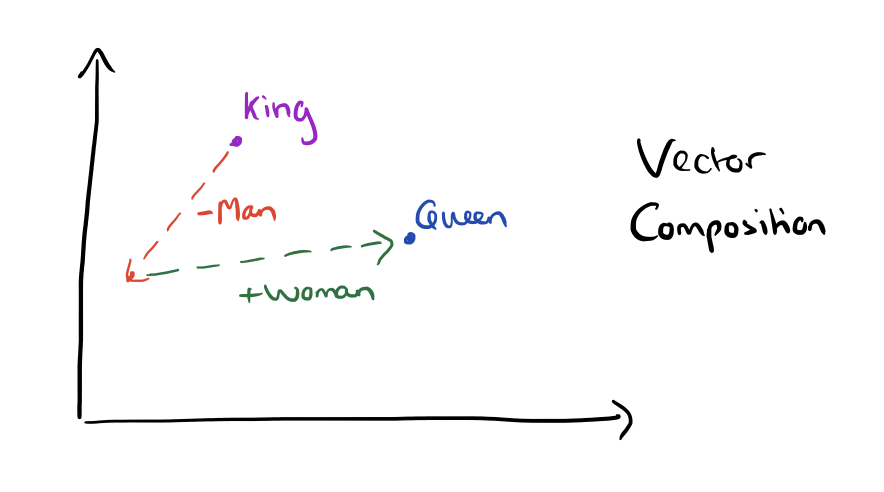
vector("car") - vector("cars") ~= vector("family") - vector("families")man -> woman ~= uncle -> auntuncle - man + woman = auntThis algebra can be described as vector composition!
So word vectors are vector representation of words, that allow us to simply encode semantic relationships.
Very complex problem in terms of runtime. We could plug it into a neural network with a training set, but it is relatively slow.
Continuous Bag-of-Words model